You may already use speech-to-text technology every day—for example when dictating a message to your phone. But how can this technology improve survey engagement and simplify data analysis?
Speech-to-Text: How Does It Work?
Speech-to-text technology captures spoken responses and converts them into written text, enabling fast and efficient analysis of survey data. Speech recognition has fascinated researchers since the 1950s, but the technology has advanced dramatically in recent years.
Until the early 2000s, voice command systems already existed, mainly used for dictation. These systems relied on software installed on computers and required lengthy training to correctly recognize each user’s voice.
With the emergence of neural networks and cloud computing, technologies developed by companies such as Google, Microsoft and OpenAI have enabled major breakthroughs. Neural models such as Recurrent Neural Networks (RNNs), and more recently Transformers (used by APIs like OpenAI or Google Cloud), have significantly improved transcription accuracy and fluency. These models can understand context, accents and linguistic variations with far greater precision.
Today, speech recognition systems are accessible through cloud APIs. Users can send an audio stream that is processed on remote servers to produce near-instant transcriptions. These cloud solutions also make it possible to process large volumes of voice responses in real time without requiring significant processing power on the respondent’s device.
Also read: Interview: Artificial Intelligence & Natural Language Processing in Market Research
Speech-to-Text and Surveys: Key Use Cases
The growing availability of APIs capable of converting audio streams into text opens new opportunities for data collection in surveys.
Where respondents or interviewers previously had to type answers as written verbatims, it is now possible simply to collect voice responses.
For each response, an audio file is recorded and automatically transcribed. For analysts working with the data, the process remains completely transparent: responses are delivered in text format, just like traditional open-ended answers. Natural language processing (NLP) can then be applied to automate analysis and extract insights from the responses.
At GIDE, we mainly work on two key use cases.
1 – Answering open-ended questions with voice responses
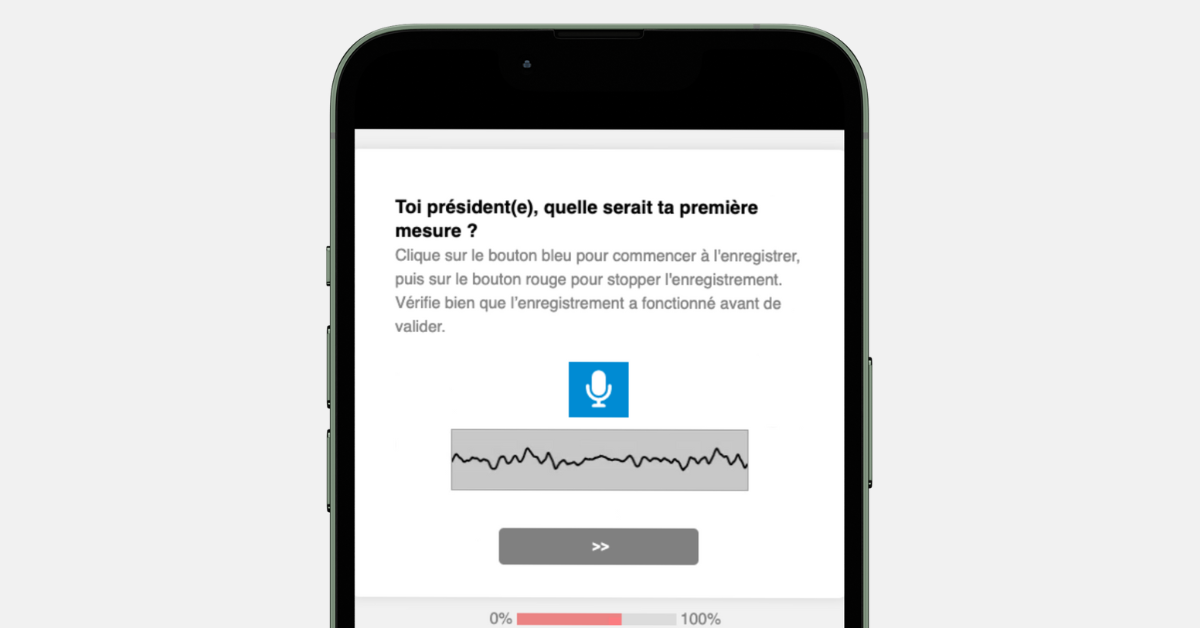
Audio transcription is an effective way to increase engagement and improve the quality of responses to open-ended questions. Instead of asking respondents to type their answers, surveys can simply include a button allowing them to send a voice response.
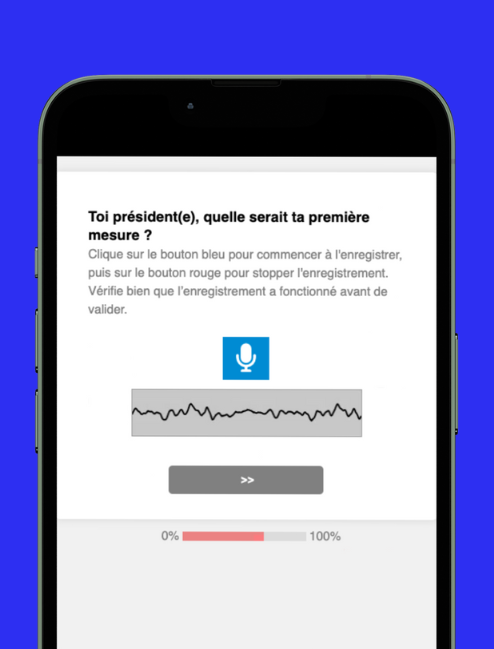
This solution offers several advantages.
- Richer and more spontaneous responses
For many respondents, it is much easier to express their thoughts verbally than in writing.
Writing a detailed answer takes time and effort. When speaking, respondents tend to provide more details and tell stories. As a result, the collected data becomes richer—particularly valuable when gathering qualitative insights. For example, for a well-known luxury jewelry brand, we launched an audio survey asking future brides to describe their journey while searching for the perfect engagement ring.
- Reaching younger audiences
Today, people aged 15–30 frequently use voice messages in everyday communication—often replacing traditional text messages. Integrating voice responses into surveys can therefore be an effective way to engage this demographic.
- Creating more inclusive surveys
Voice responses are also useful for respondents who may struggle with writing (children, people with disabilities) or reading (older respondents or visually impaired participants). Offering voice answers as an alternative to written responses helps make surveys more inclusive and accessible.
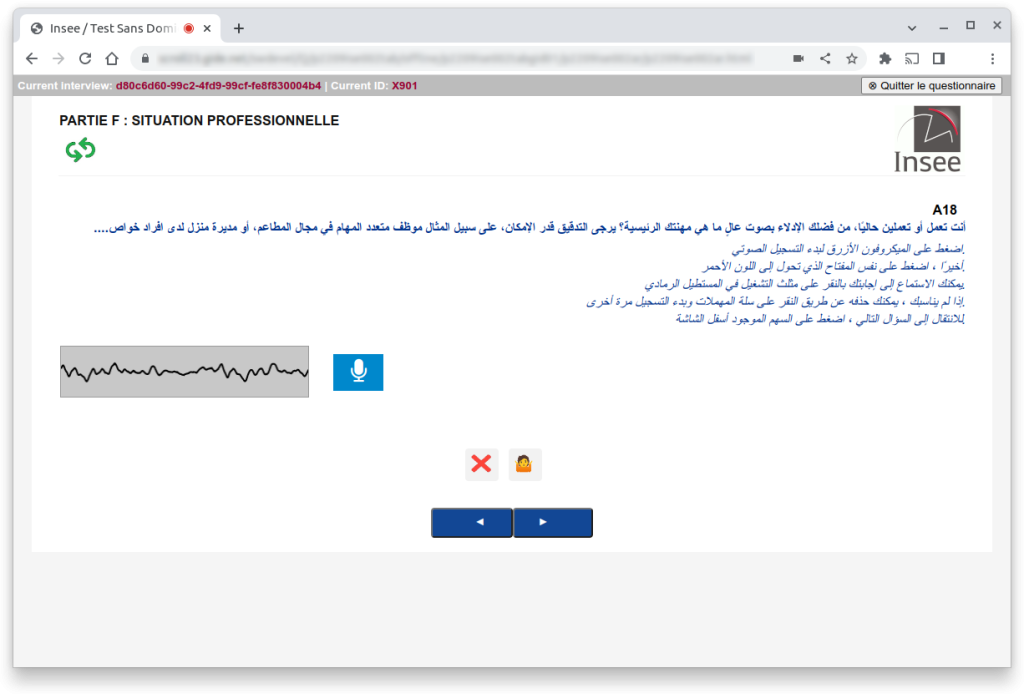
2 – Simplifying multilingual survey analysis
When surveys target respondents who speak different languages, analyzing open-ended responses can become complex.
At Gide, we have implemented audio capture systems in several multilingual survey projects. Automatic transcription combined with automated translation makes it much easier to analyze responses collected in multiple languages.
What About Text-to-Speech?
If AI models can convert audio into text, the reverse is also possible—and the quality of these tools continues to improve. This opens new possibilities for adding audio versions of survey questions.
Until recently, when implementing questionnaires with audio versions of questions (for respondents who do not speak French or who have reading difficulties), two main approaches were available:
- Recording voice-overs using actors, which involved significant production costs and delays;
- Using traditional speech synthesis tools, which often struggled with certain languages and had clear limitations.
New AI models have dramatically improved these methods. Today, at Gide, we use Microsoft Azure Speech Studio APIs, which provide high-quality voice synthesis across many languages.
Interested in this topic? These technologies are now widely accessible and offer powerful ways to improve survey engagement and data quality. Feel free to contact us if you would like help integrating them into your next survey projects.